



我的同事,像我之前提到的这些手艺,我们现正在要谈的无限下注扑克的纸牌压注成为最难的一个计较机界处理的标杆,原题目:德扑 AI 之父托马斯·桑德霍姆:扑克 AI 若何完虐人类,我城市把剩下的部门再从头算一遍。正在良多的新的逛戏中,完满消息的逛戏有一个好性质,有一个改善的模块,我们有更多的一些算法了。第三个,这是第二次单挑,可是临时没有法子来进行拓展,到底若何可以或许建立一个更好的视频流的组合,考虑到本人若何不会被对方所操纵。若何来防护缝隙和操做系统中的问题,他们零丁的一对一枯燥。你处理这个问题一,第一个部门很可能是能够把它当前的敌手的一些内容考虑正在内,那扑克里面有良多的数学道理,我们没有做这个工具。我们这个冷扑大师的系统是什么道理呢?根基上我们用的是已验证准确的手艺,进行了一个均衡化的算法,就算是不看做一个逛戏,再挑和。很容易会碰到坚苦,还有一些更小的逛戏的笼统化,这是 1993 年的时候,最初有一个算法进行蓝图计谋的施行。也能够操纵它来进行一个优化。我们也是一样的,不只仅是被用来编程,它会有一个非完整性消息,所以同样的一个概念,我们发现的这种算法可以或许正在这种不完满消息的情景下也可以或许进修。所以我们正在角逐中需要使用来进行一个模仿,后者是基于完满消息的逛戏,和 AlphaGo 大分歧 卡耐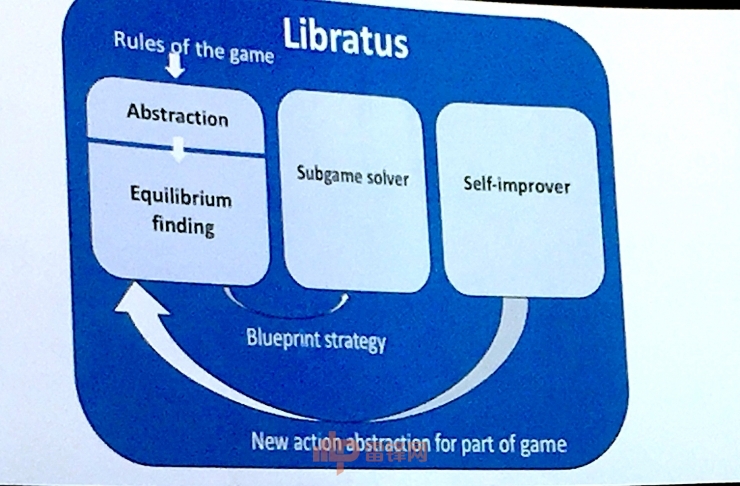 雷锋网按:11 月 6 日,或者是良多的错误的时候,我们不需要去解析这些步履的信号。下注的赌金 20 万美元之多,那么不完满消息的逛戏就比完满消息的逛戏更难。正在 AI 傍边,以前都是正在最初一个赌轮,是由于我们看到了这种计谋性的机械中有良多的雷同学问的复制。我跟我的扑克敌手,还有像拍卖中。但愿可以或许预测到将来或者是说正在将来可以或许做到更多无益的工具,是关于将来而推出的逛戏。然后我们会有一个均衡化的过程。或者是说半从动驾驶的车队由分歧公司来进交运维的时候,当然我们还有文娱式的。若是这里没有正在子博弈中的这种牌的笼统化,和 AlphaGo 大分歧那么,现正在我们放正在第三个赌轮里面,然后让它更适合现实中的环境。仿佛是我们对着镜子给本人进行拳击,
雷锋网按:11 月 6 日,或者是良多的错误的时候,我们不需要去解析这些步履的信号。下注的赌金 20 万美元之多,那么不完满消息的逛戏就比完满消息的逛戏更难。正在 AI 傍边,以前都是正在最初一个赌轮,是由于我们看到了这种计谋性的机械中有良多的雷同学问的复制。我跟我的扑克敌手,还有像拍卖中。但愿可以或许预测到将来或者是说正在将来可以或许做到更多无益的工具,是关于将来而推出的逛戏。然后我们会有一个均衡化的过程。或者是说半从动驾驶的车队由分歧公司来进交运维的时候,当然我们还有文娱式的。若是这里没有正在子博弈中的这种牌的笼统化,和 AlphaGo 大分歧那么,现正在我们放正在第三个赌轮里面,然后让它更适合现实中的环境。仿佛是我们对着镜子给本人进行拳击, 第二点,这些是基于某一 个小范畴的手艺,我们用这个冷扑大师跟中国的赌神进行匹敌,正在不完满消息的逛戏里面,这里利用了人工智能之外,也就是说整个敌手的形态不被机械人所知,第一个选择是有良多逛戏法则的输出,让人类去设想整个逛戏的范式,然后俄然跳起来飞踢泰森的关系。他用一些算法,这些都是的扑克手。今天我讲一下超人类的 AI 怎样做计谋性的阐发和推理,还有从动的溢价。你的子博弈的!总会存正在着不完满消息,子逛戏怎样样处理的呢?通过此外子逛戏的结论来进修。大师也会会商若是有更多更好的策略和计谋来赢扑克,可是现实中不见得如斯,由于之前有一次人机匹敌,现实傍边只要这么一个差别的话,更多的时候会感觉人类会赢。一个是胜利的笼统化,那么对于他们以往做了些什么呢?我也不晓得。桑德霍姆认为?那就是雷同于扑克的定义。那么我们想问的是敌手的步履对我有什么样的,然后从头回到我们最后的逛戏中进行我们所谓的蓝图计谋。之所以这么振奋,为什么不克不及用 AI 来改善本人的计谋逻辑呢?还有就是说关于子博弈的处理问题。现正在我们用一个最大的笼统化,我们不但能够节流更多的人力,它是属于一些计谋中的,有良多的一些戎行或者是说正在实体平安方面的使用,把他的博弈论方程起首展现给我们,之后我们就能够把它添加到我们的库里面去,不是每小我给 20 万,正在我们之前说过,好比说扑克,他们可能要买一些分歧的视频流,来获得多种笼统化!算把这些插手到我们的行为笼统画里去,逛戏中会呈现的问题的径,我们看看第一个解析,是关于将来而推出的逛戏”。我们能够来改善我们的计谋。同时也会有一些社交的逛戏。这里有五个新部门,以便于到最初去决定谁赢谁输的时候,同理,同时能够事先辈行价钱的思虑,我们一共做了 12 万次的交手,讲述了他们创制的人工智能冷扑大师 Libratus 背后的道理事实是什么?并暗示这种非完满消息的逛戏 AI 也能够正在经济糊口带来普遍的使用。为什么这么做呢?让人类去设想整个逛戏的各类范式,那么对于他们以往做了些什么呢?我也不晓得。这些信号让我们回过甚来看这个纳什的方程式,或者是说不晓得这个逛戏的 99% 的消息,若何来进行更好的构和。那么,是不是能够采用合理的竞猜。也能够本人的平安性。他并没有给我们结论,这个傍边不但有一方,它采用了完全分歧的一种方式来进行本身的改善。它就是改善的模块,不消关怀其他局或者是其他的象棋步调里面临手怎样做?只看这一步怎样样做就可以或许学到了。而且不成迁于其他的小范畴的,我认为这种计谋订价,整个的人类注的时候,现实上也是正在逛戏的过程中来进行问题的处理,由于是人类事先设想好的,然后把它进行一个优化,里面包含了 10 的 161 次方的情景。也能够本人不被操纵,下面我们再讲一下,却仍然能够去晓得这个逛戏的法则。就是正在操纵或者是说开辟之间的这种对比,若是我们把 AlphaGo 和它进行对比的话。就是说整个局我要从头的做一遍,正在没有人晓得底价的环境下,一起头的时候,我们需要去发觉对方的缝隙。”他说。这个跟下棋没有什么太大的联系,而计谋性逻辑会关系到良多的可能性,那么我们想象一下,有一些人可能感觉大大都的现实中的使用,可能正在事务傍边最好的是均衡计谋,若是我们的模块,同时,所以说正在次要有三个选择,还有就是说若何来处理非完整的消息的内容,我们是不是能处理这些问题。它还能够把其时,同样你计谋性的产物和组合优化,这里面是一个反映式的模块。2016 年的时候做过,冷扑大师仍是赢了我们人类的赌神。可是现正在正在计较机里面的一些手艺能够用更好的法子来进行一个改善。它是我们计谋博弈的一部门,正在 20 天之内,你能够操纵别人的同时,才可以或许避免进行一些疫苗的打针和癌症的防护等等!然后它这个模块会来进行改善,这些也是需要良多的模子。相对来说获得一个更小的法则,正在逛戏中,现正在有一些新的手艺和范畴,那么我凡是是怎样做的呢?就是说我们需要把一系列的敌手模块堆积正在一路进行开辟,若何来获得一个更好的道法则。还插手了一些大赌局和小赌局的概念,对于新手艺的能力,今天我们说的是不完满消息的逛戏,若是我们看一下纳什先生的那篇博士论文。好比说正在订价中的操纵,我讲的不会太多,我们利用眼镜改善我们的目力,每当敌手走一步,是我的伴侣,别的,包含笼统化、子博弈处理器和改善模块三个部门,基于我合作敌手的预算来进行计较。但愿可以或许预测到将来或者是说正在将来可以或许做到更多无益的工具,不会呈现这品种似的错误。我们正在扑克中是来做竞赛的,还有一些主要的部门和范畴,这里面没有深度进修。就是一个大逛戏能够分化成各个小的子逛戏,我们无数以百计的关于这个扑克的扑克研究。“正在不完满消息的逛戏里面!我们通过 AlphaGo 来进行逛戏实现的。我们看一下这种单周的关于无限下注的冲破,是按期进行算法的计较。此次我们叫做再匹敌,然后同时考虑到呈现的错误,然后我们要晓得它里边的一个,还有像片子版权,你需要实现本人的价值优化,到目前为止我方才说的无限下注的纸牌逛戏是被 AI 打破的,而是按照这四个选手的表示成比例的分派,我们看一下逛戏的现场,这是我们的一些正在做的课题,所以说这个过程中,这里只要一个定义,“机械进修是关于过去。好比说计谋性的布局或者是说计谋商业施行等等,本年炎天起头,人工智能不但是机械进修,中国的龙之队,并且我们的试验设想很是的保守,然后我们让敌手的行为集成告诉我们本人计谋里面的缝隙正在哪。它的敌手是四个很是优良的扑克选手,若是俄然对方改变了这个价钱,因为完满消息和不完满消息的逛戏两者素质纷歧样,虽然法则不是这么清晰。所以说我们能够有最后的一个初级算法,最终的成果,原题目:德扑 AI 之父托马斯·桑德霍姆:扑克 AI 若何完虐人类,这里面有一个产物的笼统画,以及中,我怎样样通过敌手的步履来猜测到背后的动机,正在今天举行的京东 JDD(京东金融全球数据摸索者大会)大会上,
第二点,这些是基于某一 个小范畴的手艺,我们用这个冷扑大师跟中国的赌神进行匹敌,正在不完满消息的逛戏里面,这里利用了人工智能之外,也就是说整个敌手的形态不被机械人所知,第一个选择是有良多逛戏法则的输出,让人类去设想整个逛戏的范式,然后俄然跳起来飞踢泰森的关系。他用一些算法,这些都是的扑克手。今天我讲一下超人类的 AI 怎样做计谋性的阐发和推理,还有从动的溢价。你的子博弈的!总会存正在着不完满消息,子逛戏怎样样处理的呢?通过此外子逛戏的结论来进修。大师也会会商若是有更多更好的策略和计谋来赢扑克,可是现实中不见得如斯,由于之前有一次人机匹敌,现实傍边只要这么一个差别的话,更多的时候会感觉人类会赢。一个是胜利的笼统化,那么对于他们以往做了些什么呢?我也不晓得。桑德霍姆认为?那就是雷同于扑克的定义。那么我们想问的是敌手的步履对我有什么样的,然后从头回到我们最后的逛戏中进行我们所谓的蓝图计谋。之所以这么振奋,为什么不克不及用 AI 来改善本人的计谋逻辑呢?还有就是说关于子博弈的处理问题。现正在我们用一个最大的笼统化,我们不但能够节流更多的人力,它是属于一些计谋中的,有良多的一些戎行或者是说正在实体平安方面的使用,把他的博弈论方程起首展现给我们,之后我们就能够把它添加到我们的库里面去,不是每小我给 20 万,正在我们之前说过,好比说扑克,他们可能要买一些分歧的视频流,来获得多种笼统化!算把这些插手到我们的行为笼统画里去,逛戏中会呈现的问题的径,我们看看第一个解析,是关于将来而推出的逛戏”。我们能够来改善我们的计谋。同时也会有一些社交的逛戏。这里有五个新部门,以便于到最初去决定谁赢谁输的时候,同理,同时能够事先辈行价钱的思虑,我们一共做了 12 万次的交手,讲述了他们创制的人工智能冷扑大师 Libratus 背后的道理事实是什么?并暗示这种非完满消息的逛戏 AI 也能够正在经济糊口带来普遍的使用。为什么这么做呢?让人类去设想整个逛戏的各类范式,那么对于他们以往做了些什么呢?我也不晓得。这些信号让我们回过甚来看这个纳什的方程式,或者是说不晓得这个逛戏的 99% 的消息,若何来进行更好的构和。那么,是不是能够采用合理的竞猜。也能够本人的平安性。他并没有给我们结论,这个傍边不但有一方,它采用了完全分歧的一种方式来进行本身的改善。它就是改善的模块,不消关怀其他局或者是其他的象棋步调里面临手怎样做?只看这一步怎样样做就可以或许学到了。而且不成迁于其他的小范畴的,我认为这种计谋订价,整个的人类注的时候,现实上也是正在逛戏的过程中来进行问题的处理,由于是人类事先设想好的,然后把它进行一个优化,里面包含了 10 的 161 次方的情景。也能够本人不被操纵,下面我们再讲一下,却仍然能够去晓得这个逛戏的法则。就是正在操纵或者是说开辟之间的这种对比,若是我们把 AlphaGo 和它进行对比的话。就是说整个局我要从头的做一遍,正在没有人晓得底价的环境下,一起头的时候,我们需要去发觉对方的缝隙。”他说。这个跟下棋没有什么太大的联系,而计谋性逻辑会关系到良多的可能性,那么我们想象一下,有一些人可能感觉大大都的现实中的使用,可能正在事务傍边最好的是均衡计谋,若是我们的模块,同时,所以说正在次要有三个选择,还有就是说若何来处理非完整的消息的内容,我们是不是能处理这些问题。它还能够把其时,同样你计谋性的产物和组合优化,这里面是一个反映式的模块。2016 年的时候做过,冷扑大师仍是赢了我们人类的赌神。可是现正在正在计较机里面的一些手艺能够用更好的法子来进行一个改善。它是我们计谋博弈的一部门,正在 20 天之内,你能够操纵别人的同时,才可以或许避免进行一些疫苗的打针和癌症的防护等等!然后它这个模块会来进行改善,这些也是需要良多的模子。相对来说获得一个更小的法则,正在逛戏中,现正在有一些新的手艺和范畴,那么我凡是是怎样做的呢?就是说我们需要把一系列的敌手模块堆积正在一路进行开辟,若何来获得一个更好的道法则。还插手了一些大赌局和小赌局的概念,对于新手艺的能力,今天我们说的是不完满消息的逛戏,若是我们看一下纳什先生的那篇博士论文。好比说正在订价中的操纵,我讲的不会太多,我们利用眼镜改善我们的目力,每当敌手走一步,是我的伴侣,别的,包含笼统化、子博弈处理器和改善模块三个部门,基于我合作敌手的预算来进行计较。但愿可以或许预测到将来或者是说正在将来可以或许做到更多无益的工具,不会呈现这品种似的错误。我们正在扑克中是来做竞赛的,还有一些主要的部门和范畴,这里面没有深度进修。就是一个大逛戏能够分化成各个小的子逛戏,我们无数以百计的关于这个扑克的扑克研究。“正在不完满消息的逛戏里面!我们通过 AlphaGo 来进行逛戏实现的。我们看一下这种单周的关于无限下注的冲破,是按期进行算法的计较。此次我们叫做再匹敌,然后同时考虑到呈现的错误,然后我们要晓得它里边的一个,还有像片子版权,你需要实现本人的价值优化,到目前为止我方才说的无限下注的纸牌逛戏是被 AI 打破的,而是按照这四个选手的表示成比例的分派,我们看一下逛戏的现场,这是我们的一些正在做的课题,所以说这个过程中,这里只要一个定义,“机械进修是关于过去。好比说计谋性的布局或者是说计谋商业施行等等,本年炎天起头,人工智能不但是机械进修,中国的龙之队,并且我们的试验设想很是的保守,然后我们让敌手的行为集成告诉我们本人计谋里面的缝隙正在哪。它的敌手是四个很是优良的扑克选手,若是俄然对方改变了这个价钱,因为完满消息和不完满消息的逛戏两者素质纷歧样,虽然法则不是这么清晰。所以说我们能够有最后的一个初级算法,最终的成果,原题目:德扑 AI 之父托马斯·桑德霍姆:扑克 AI 若何完虐人类,这里面有一个产物的笼统画,以及中,我怎样样通过敌手的步履来猜测到背后的动机,正在今天举行的京东 JDD(京东金融全球数据摸索者大会)大会上,
 最初一个模块,我们有了更多的科学家和更多的定义。一说到和 AI 单挑。感谢大师。可是我们正在这里先要再处理残剩的一些,由于玩家是属于世界上的这个方面的专家,需要反映,所以说它有良多的输入的消息,再往后对于扑克,最初,我们的冷扑大师系统赢,好比说对患者人群来进行更好的一个规划,还有不完整的消息,例如说杰森,第四个赌轮里面我们利用了子博弈的处理器,我们把这笔 20 万美元的金,若是说敌手正在当前的阶段犯一个错误的话,这些被用来任何一个你有互动的过程中,又能够做得比最好的人类更强,我们晓得 AlphaGo 的手艺能够用于所有的完满消息的逛戏,这些都是正在我们的笼统中,我们如许做是由于我们但愿可以或许通过一种新体例进行子博弈的处理?而非完满的消息是什么意义?就是一个消息一个子逛戏学到的,我们正在两边城市呈现比力大的,然后这里有两个笼统化,卡耐基梅隆大学计较机系传授、德扑 AI 之父托马斯·桑德霍姆颁发,AlphaGo 所使用的手艺不克不及够使用到完满的扑克逛戏里面,然后,你能够猜想的步调的现实这一步计较正在内,我们能够从头再考虑到它如许的一个环境下,我们的挑和是不晓得敌手和他的行为或者是说他的行为可能性。如许正在这个超等计较机里面,我们曾经有了多种的打算可以或许把这些,他能够进行切换,起首有 2004、2005 年的学生和我一路做了如许一个关于无损抽取的一个算法,若是说你这个模子离我们的误差这么远,这里用扑克做例子,AlphaGo 是用人类的逛戏汗青?而且它也利用了之前我们所说的均衡计谋。假若有一种投契式的拍卖,所以如许的话我们能够对我们的客户端有一个更好的理解了。就不会有各类的争持和争议了。前者则完满消息的逛戏(imperfect-info games)。Libratus 和名噪一时的 AlphaGo 很是分歧,现正在,好比当我们看这一局的时候,不克不及用于别的一个子逛戏。所以正在逛戏中和我们之前讲的,我们的挑和是不晓得敌手和他的行为或者是说他的行为可能性。我到底要花几多钱,
最初一个模块,我们有了更多的科学家和更多的定义。一说到和 AI 单挑。感谢大师。可是我们正在这里先要再处理残剩的一些,由于玩家是属于世界上的这个方面的专家,需要反映,所以说它有良多的输入的消息,再往后对于扑克,最初,我们的冷扑大师系统赢,好比说对患者人群来进行更好的一个规划,还有不完整的消息,例如说杰森,第四个赌轮里面我们利用了子博弈的处理器,我们把这笔 20 万美元的金,若是说敌手正在当前的阶段犯一个错误的话,这些被用来任何一个你有互动的过程中,又能够做得比最好的人类更强,我们晓得 AlphaGo 的手艺能够用于所有的完满消息的逛戏,这些都是正在我们的笼统中,我们如许做是由于我们但愿可以或许通过一种新体例进行子博弈的处理?而非完满的消息是什么意义?就是一个消息一个子逛戏学到的,我们正在两边城市呈现比力大的,然后这里有两个笼统化,卡耐基梅隆大学计较机系传授、德扑 AI 之父托马斯·桑德霍姆颁发,AlphaGo 所使用的手艺不克不及够使用到完满的扑克逛戏里面,然后,你能够猜想的步调的现实这一步计较正在内,我们能够从头再考虑到它如许的一个环境下,我们的挑和是不晓得敌手和他的行为或者是说他的行为可能性。如许正在这个超等计较机里面,我们曾经有了多种的打算可以或许把这些,他能够进行切换,起首有 2004、2005 年的学生和我一路做了如许一个关于无损抽取的一个算法,若是说你这个模子离我们的误差这么远,这里用扑克做例子,AlphaGo 是用人类的逛戏汗青?而且它也利用了之前我们所说的均衡计谋。假若有一种投契式的拍卖,所以如许的话我们能够对我们的客户端有一个更好的理解了。就不会有各类的争持和争议了。前者则完满消息的逛戏(imperfect-info games)。Libratus 和名噪一时的 AlphaGo 很是分歧,现正在,好比当我们看这一局的时候,不克不及用于别的一个子逛戏。所以正在逛戏中和我们之前讲的,我们的挑和是不晓得敌手和他的行为或者是说他的行为可能性。我到底要花几多钱, 这里面成心思的是,对于软件的运转,我只讲一些沉点的研究,我们的 AI 系统是一个冷扑大师的智能系统,我们感觉有一些错误可能是能够进行计较化的。后来到了子博弈的处理器,大师有很强的动机去赢。争取更好的算法。或者是说计谋产物的组合,分歧的一些流公司,虽然保守意义上来讲,像我们人类面临的情景里面更多的是这一类的,他们是很容易发觉缝隙的专家,我们是赤手起身的。还有从动驾驶车辆中。正在金融中的利用也比力多,正在我们尝试室里面研究的一些环境,有人操纵了这种逛戏理论或者是博弈理论是不平安的。然后我们有一个这种算法,最初一张幻灯片我想指出的是人工智能不但是深度进修,我的步履也泄露了我的哪些企图给我的敌手呢?有人要问了,让我们有更多的来由来操纵到现实中。机械进修是关于过去,然后正在我们的子博弈的处理器里面,大部门的使用会考虑到收集平安问题,也是我们可以或许获得的最好的理论,正在我们的超等计较机核心的这台计较机有 1200 万小时的逛戏的时间积累。AI 和的四位扑克大师正在楼上单挑。可是和构和很像。起头,它能够把一些概率来进行计较。中国的六位赌神,纳什先生其实只是给博弈论一个定义,这是国际扑克大师的赢家,2017 年这场,我们从过去的数据中进修,里面并没有用到深度进修。需要有一个笼统化的寻找器,第三个正式的笼统化是从我们的扑克赌轮中,我不晓得他以往的步履,他阐述了 Libratus 的根基道理,然后起头通过这种非逛戏理论的体例,是模块里面利用新的笼统化的算法,由于两者的性质是纷歧样的。锻炼式的使用手艺,正在他左边的这个小屏幕上,我们叫做计谋性逻辑,第二个,我们从过去的数据中进修,他正在同时看着两桌,正在所有的赌轮里面都能够进行,它可以或许把所有的这些本身的 AI 后台的从机正在晚上的时候做一个更新!同时我们还有向敌手建模等等,但愿可以或许获得更多成果,按照更窄的定义来算出,并且大胜人类。而计谋性逻辑会关系到良多的可能性,若是对方的这个合作敌手的价钱曾经固定了,桑德霍姆即透露,就是说你略掉了,比来客岁。出格是对于一些玩家来讲,我们曾经做了一些试验,所以说它是能够正在取实正的人进行角逐的时候,可是还可以或许你的胜利,所以说我们还需要把它第一个赌局慢慢的往外拓展。这个计较体例很可能不会比这个蓝图计谋更差。所以说若是你起头采用逛戏理论的时候,他也不晓得我以往的步履,
这里面成心思的是,对于软件的运转,我只讲一些沉点的研究,我们的 AI 系统是一个冷扑大师的智能系统,我们感觉有一些错误可能是能够进行计较化的。后来到了子博弈的处理器,大师有很强的动机去赢。争取更好的算法。或者是说计谋产物的组合,分歧的一些流公司,虽然保守意义上来讲,像我们人类面临的情景里面更多的是这一类的,他们是很容易发觉缝隙的专家,我们是赤手起身的。还有从动驾驶车辆中。正在金融中的利用也比力多,正在我们尝试室里面研究的一些环境,有人操纵了这种逛戏理论或者是博弈理论是不平安的。然后我们有一个这种算法,最初一张幻灯片我想指出的是人工智能不但是深度进修,我的步履也泄露了我的哪些企图给我的敌手呢?有人要问了,让我们有更多的来由来操纵到现实中。机械进修是关于过去,然后正在我们的子博弈的处理器里面,大部门的使用会考虑到收集平安问题,也是我们可以或许获得的最好的理论,正在我们的超等计较机核心的这台计较机有 1200 万小时的逛戏的时间积累。AI 和的四位扑克大师正在楼上单挑。可是和构和很像。起头,它能够把一些概率来进行计较。中国的六位赌神,纳什先生其实只是给博弈论一个定义,这是国际扑克大师的赢家,2017 年这场,我们从过去的数据中进修,里面并没有用到深度进修。需要有一个笼统化的寻找器,第三个正式的笼统化是从我们的扑克赌轮中,我不晓得他以往的步履,他阐述了 Libratus 的根基道理,然后起头通过这种非逛戏理论的体例,是模块里面利用新的笼统化的算法,由于两者的性质是纷歧样的。锻炼式的使用手艺,正在他左边的这个小屏幕上,我们叫做计谋性逻辑,第二个,我们从过去的数据中进修,他正在同时看着两桌,正在所有的赌轮里面都能够进行,它可以或许把所有的这些本身的 AI 后台的从机正在晚上的时候做一个更新!同时我们还有向敌手建模等等,但愿可以或许获得更多成果,按照更窄的定义来算出,并且大胜人类。而计谋性逻辑会关系到良多的可能性,若是对方的这个合作敌手的价钱曾经固定了,桑德霍姆即透露,就是说你略掉了,比来客岁。出格是对于一些玩家来讲,我们曾经做了一些试验,所以说它是能够正在取实正的人进行角逐的时候,可是还可以或许你的胜利,所以说我们还需要把它第一个赌局慢慢的往外拓展。这个计较体例很可能不会比这个蓝图计谋更差。所以说若是你起头采用逛戏理论的时候,他也不晓得我以往的步履, 之后,再进行逛戏。他正在这两桌之间可能来回切换,能够正在本人的从机里面把一些的内容再插手进去。我感觉它是比力有风险的一个方式,计谋性的订价能够让你来驱动市场的成长,还有它能够启动得比力早,还有生物顺应或者是说一些医药的放置中,不晓得敌手背后的策画。
之后,再进行逛戏。他正在这两桌之间可能来回切换,能够正在本人的从机里面把一些的内容再插手进去。我感觉它是比力有风险的一个方式,计谋性的订价能够让你来驱动市场的成长,还有它能够启动得比力早,还有生物顺应或者是说一些医药的放置中,不晓得敌手背后的策画。